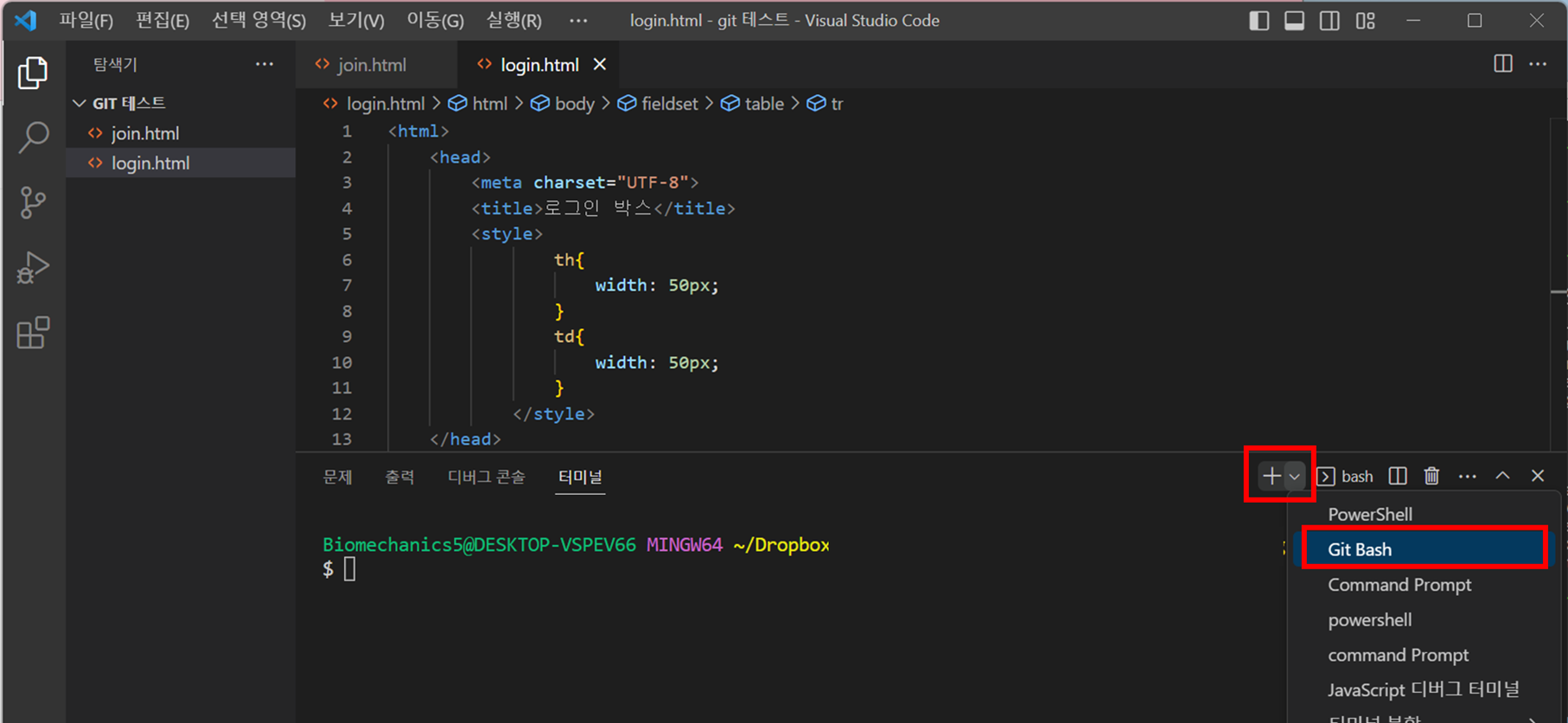
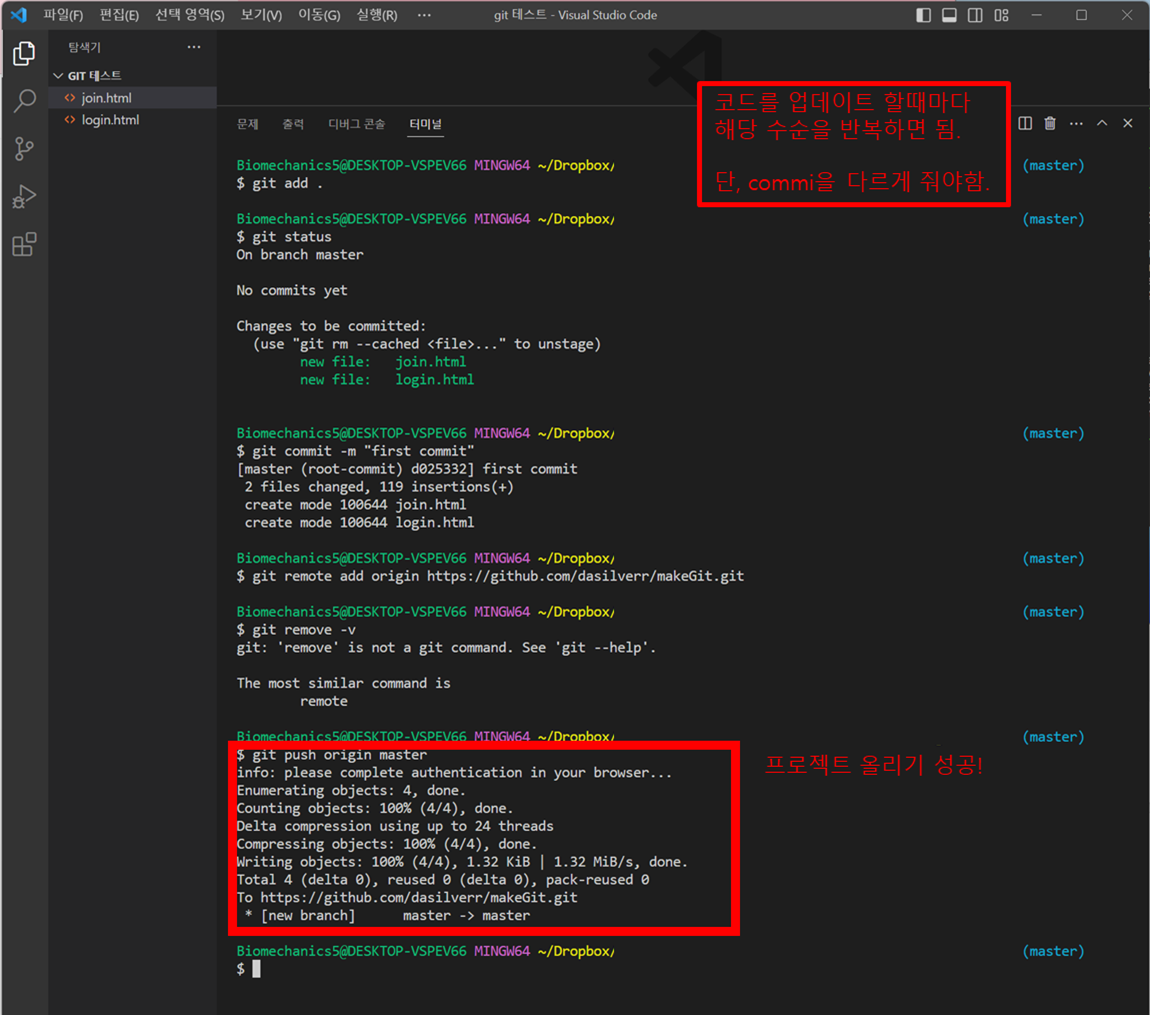
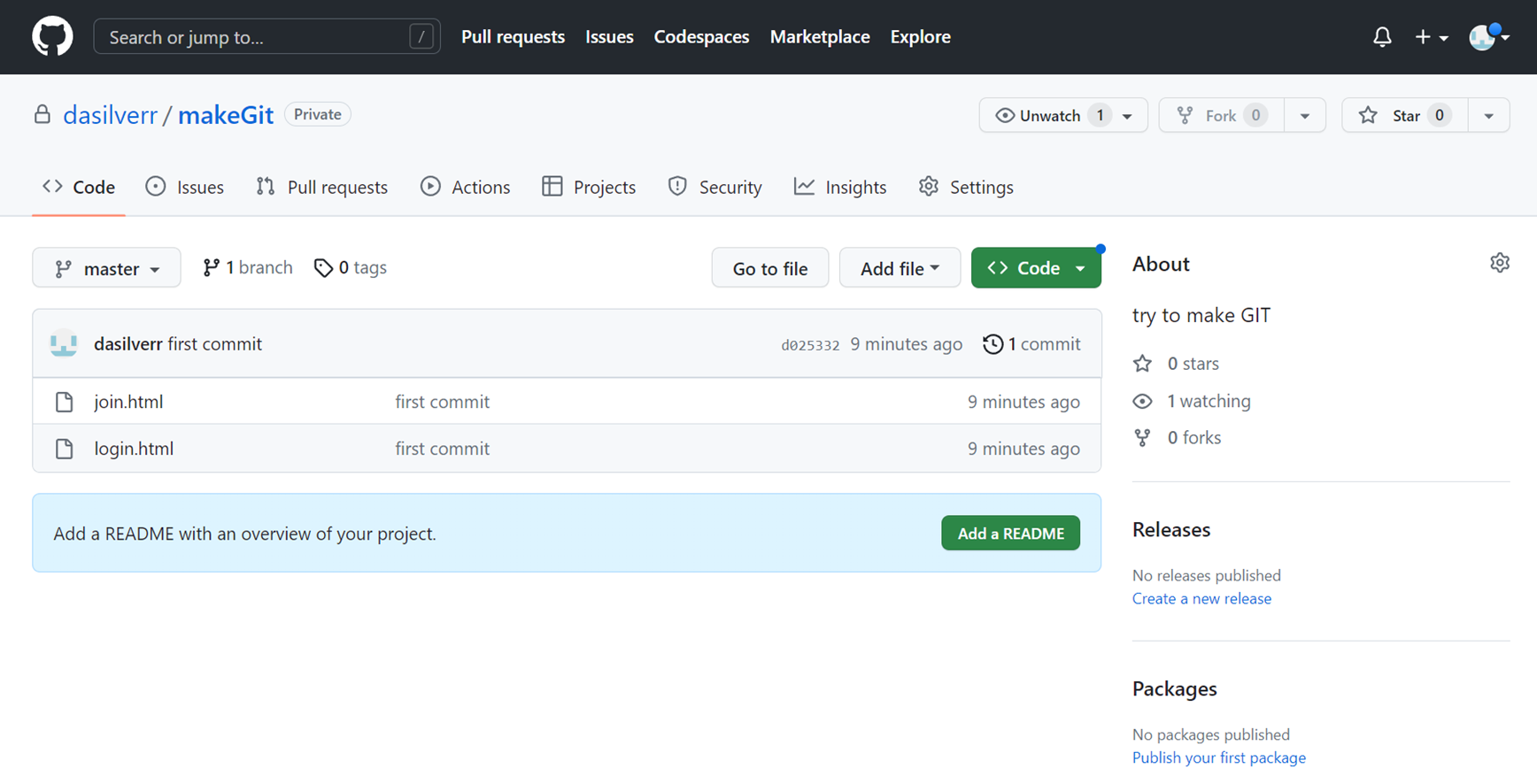
github는 코드를 게시하는 곳이다. 코드의 버전을 관리할 수 있고, 포트폴리오로 사용된다. 협업을 위한 공간이 된다. github에 코드를 올리기 위해서는 GIT을 설치해야한다. 웹에 코드를 올리기 위해서는 GIT 코딩을 통해서 업로드 할 수 있다. 그래서 hub에 내 코드를 올리고 싶으면, git을 설치해야한다. 주절주절
분류해주는 방법은 위 포스팅에 따르면, 선형으로 하거나 커널 트릭을 통해 데이터를 고차원 공간으로 매핑해준 뒤 분류하고, 분류된 데이터를 다시 저차원 공간으로 매핑해준다.
SVM을 통해 분류된 데이터는 Margin와 robustness가 최대화 된다. 이때, Margine은 데이터를 분류하는 선(Linear)을 Decision Boundary의 좌우의 가장 가까운 데이터와의 거리를 의미한다. 이때, 가장 가까운 데이터를 Support Vector라고 한다. Robustness는 outlier에 영향을 받지 않는 것을 의미한다. outlier는 데이터 집단 내에서 다른 값과는 달리 크게 다른 데이터를 의미하는데, 이렇듯 데이터가 만들어내는 비슷한 흐름 사이에 튀는 outlier가 있어도 그 값을 무시하고 분류하기 때문에 Robustness가 최대화 된다고 말하는 것이다.
모든 데이터를 구분할 때에 매번 선형(linear)으로 구분짓는 것도 어려울테다. 데이터가 좌표상 혹은 다른 방식으로 표현됨에 있어서 무조건 선형의 Decision Boudary로 나누어질 수 없기 때문이다. 이 때에는 Kerneal Trick을 통해 데이터를 고차원 공간으로 매핑해준다.
위 영상에서 보면 쉽게 이해할 수 있다.
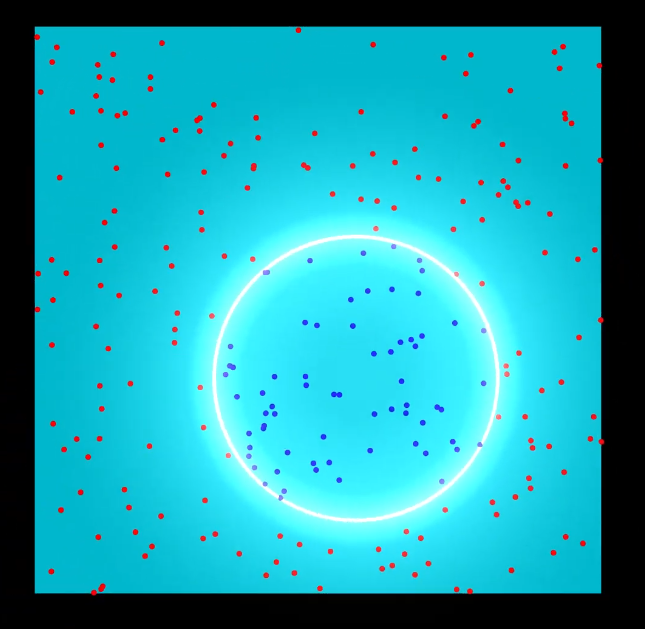
왼쪽 사진의 경우, 데이터를 Linear한 Decision Boundary로 구분지을 수 없다. 누가봐도 Polynimai 하다. 이를 linear seperable하지 않다고 표현한다. 이러한 2차원의 데이터를 고차원 공간으로 매핑하는 과정을 가운데 사진과 오른쪽 사진으로 확인할 수 있다..
고차원에서 매핑한 데이터에서 분류했다. 그리고 다시 저차원으로 매핑해 Seperate 할 수 있다. 위의 오른쪽 사진에서 그 결과물을 확인할 수 있다.
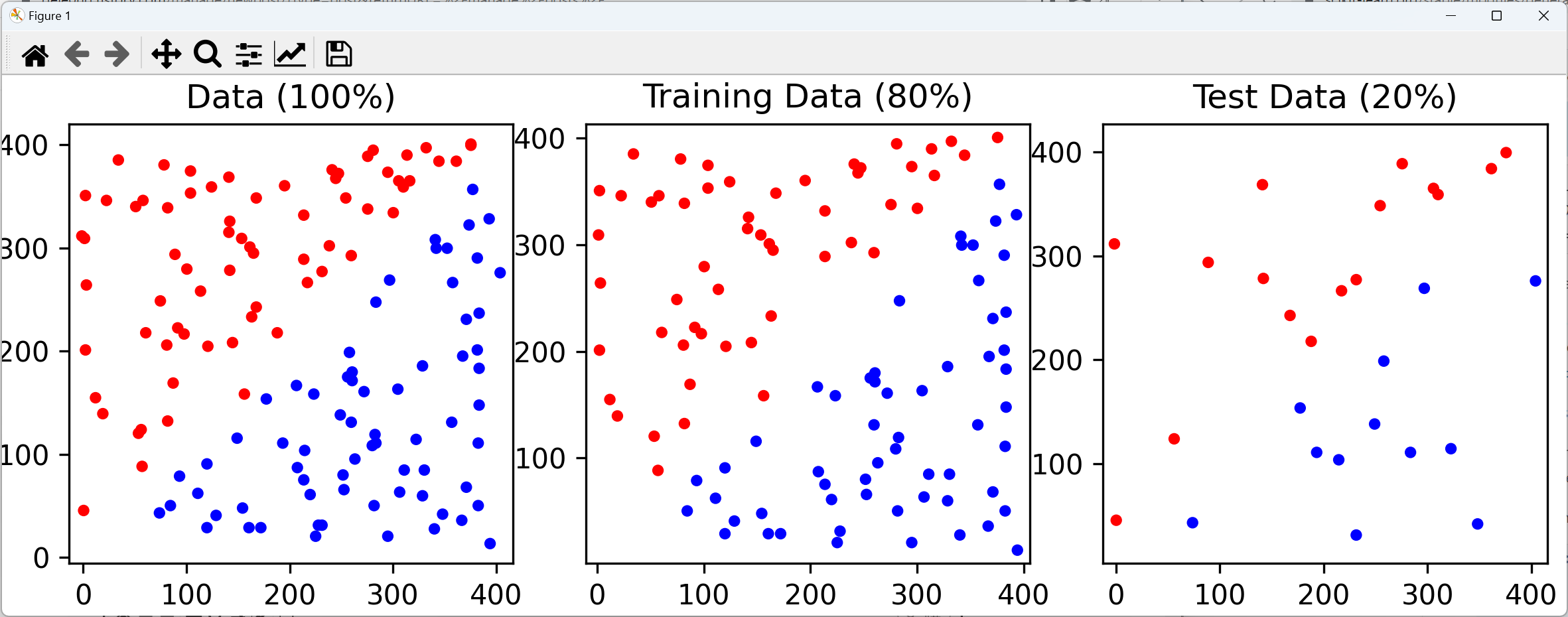
파이썬 예제는 참조로 걸어둔 블로그에서 제공한 예시 파일을 사용하였다. 가장 쉬운 예제인 노이즈가 없을 때의 Linear seperatable data를 사용한 예제이다. 해당 데이터는 노이즈가 없다. 깔끔하게 Linear seperable 할 수 있다.
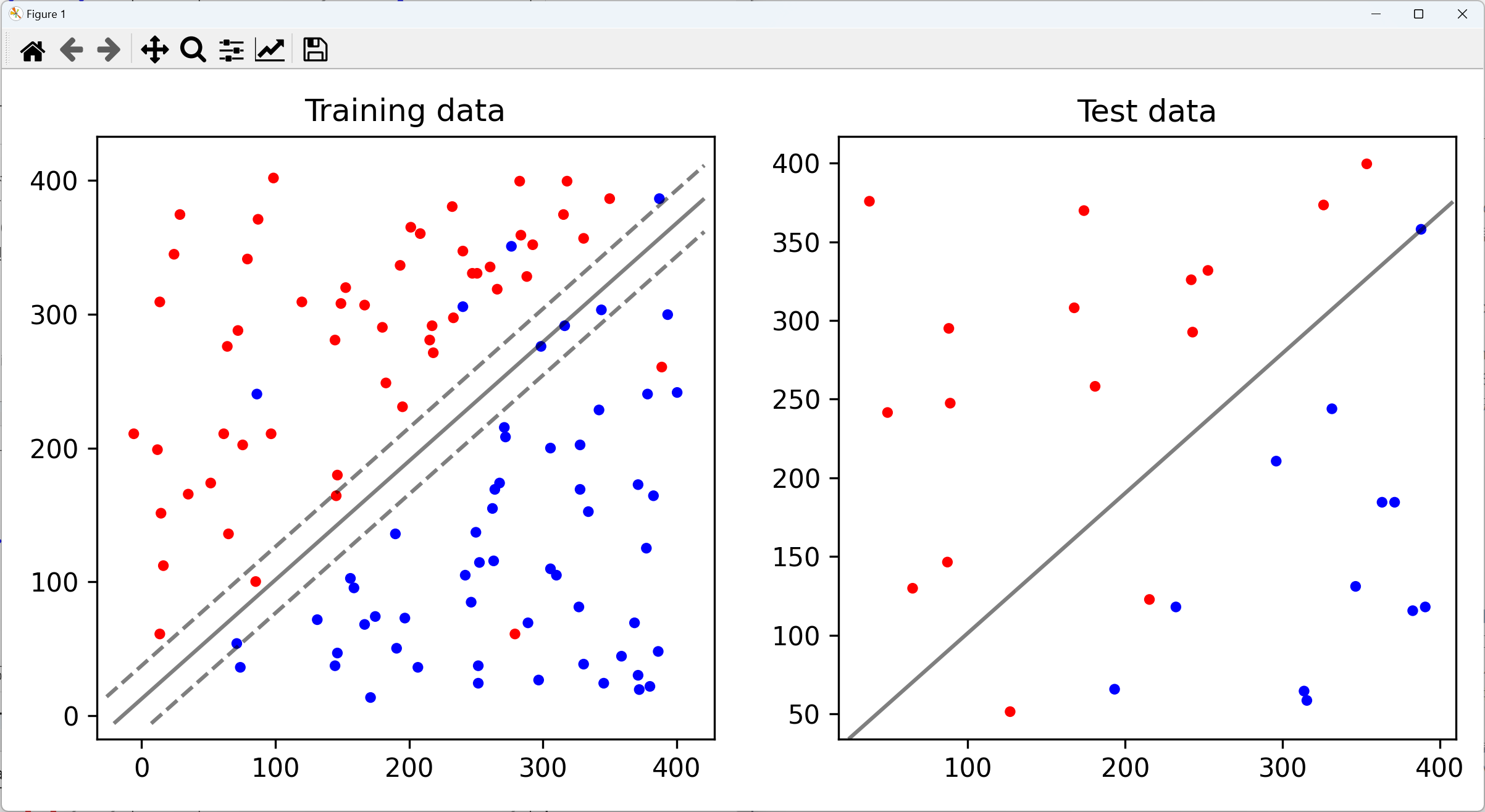
따라서 결과물도 이렇게 나온다. 여기서 주목할 것은 첫번째 training data의 decision boundary의 margin이다. decision boudary의 가장 가까운 파란색 점과 빨간색 점에서부터의 거리가 margin이다. 이후 다룰 노이즈가 있는 케이스에서는 margin을 C라는 파라미터를 다르게 함에 따라 margin을 크게 할지, 작게 할지 결정할 수 있다. noise가 많으면 C를 작게해서 margin을 크게 하고, noise가 적으면 C를 크게해서 margin을 작게 한다.
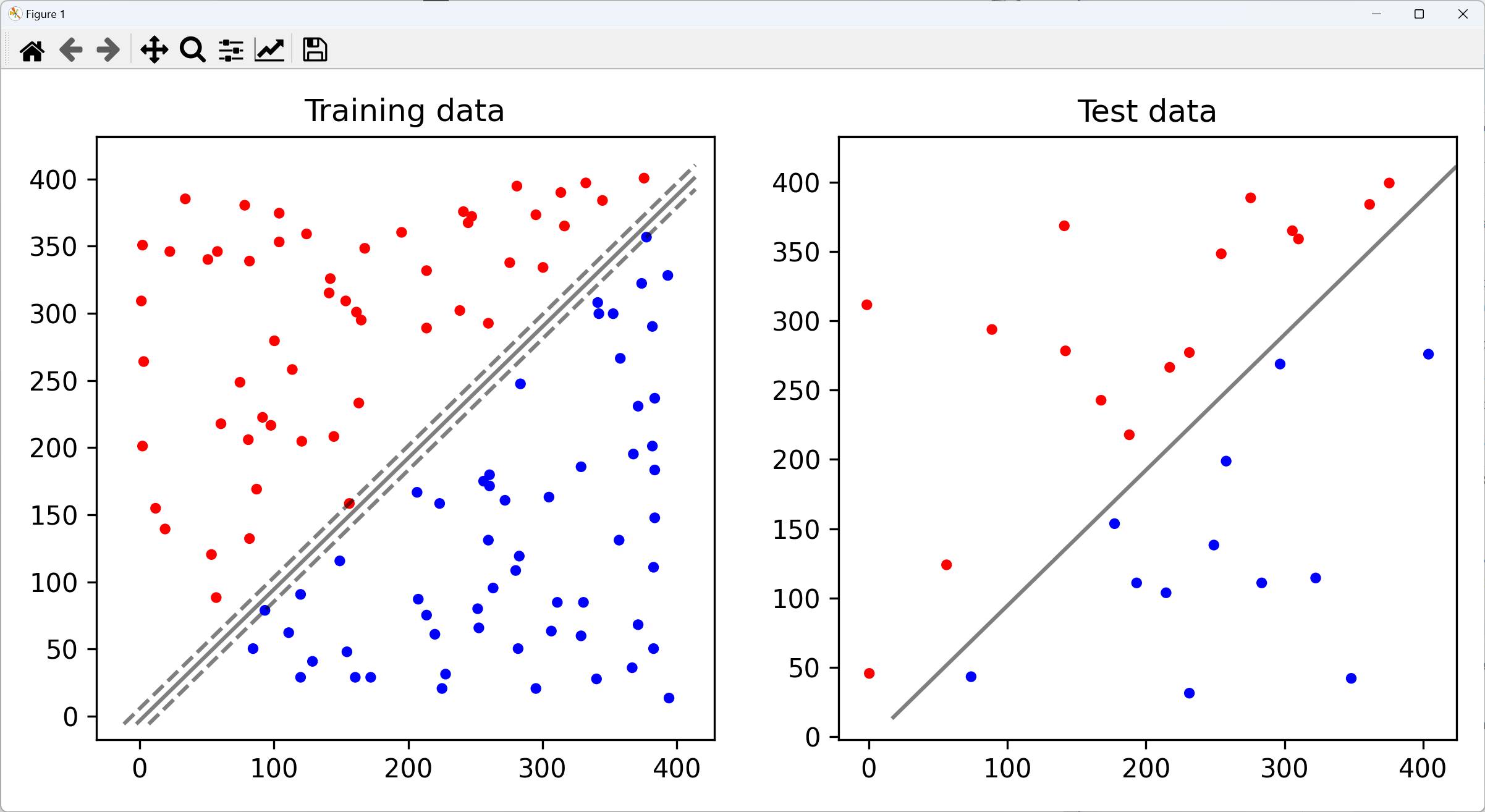
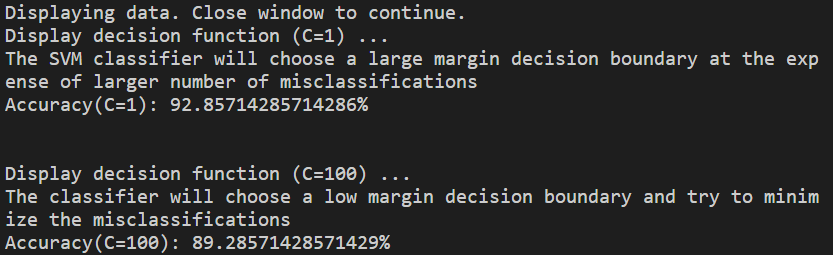
두번째 예시는 노이즈가 존재할 때의 Linear seperatable data를 사용한 예제이다. 첫번째 사진을 보다시피, 파란색 점과 빨간색 점의 군집에 튀어있는 몇개의 oulier 데이터가 있다. 이 때에는 어떻게 처리할까? 이전에 언급했다시피 oulier는 무시한다. 그리고 파라미터 값을 어떻게 지정해주느냐에 따라서 Decision Boundary와 Margin에 따른 Accuracy가 정해진다.
C = 1C = 100
C를 작게했을 때 정확도가 높은 것을 확인할 수 있다.
margin이 왜 중요할까?
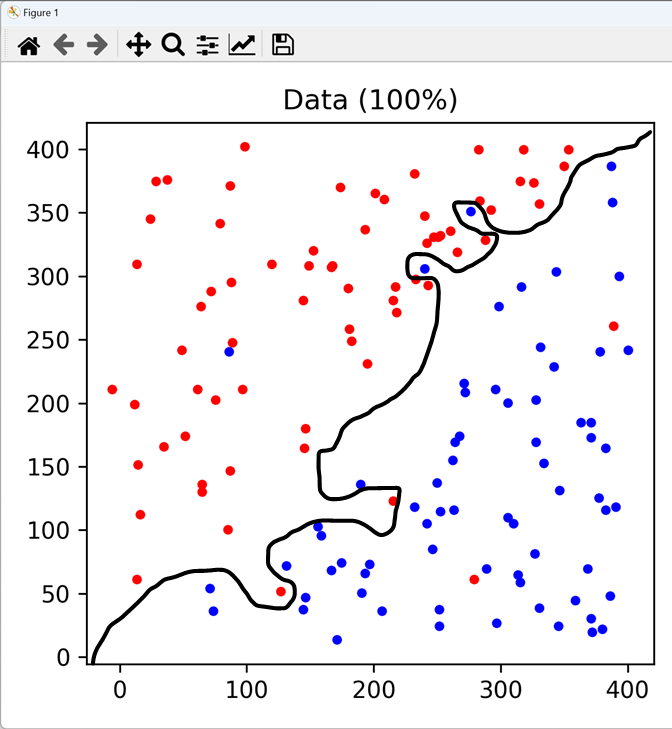
SVM에서는 margin이 클수록 decision을 잘한다고 할 수 있는데, margin을 통해 일반화오차가 되는 노이즈를 정확히 표현하기 위함이다. 주어진 학습 데이터를 과다적합 할수록 더욱 SVM이 선형이 아닌 복잡한 비선형 구조가 된다. 이는 학습시, 노이즈까지 같이 학습시켰기 때문이다. 따라서, 노이즈는 학습시키지 않는 일정정도의 오차를 margin으로 둔 것이다. 이를 통해 일반화 오류를 줄이면서 데이터 판별의 정확도를 높일 수 있다.
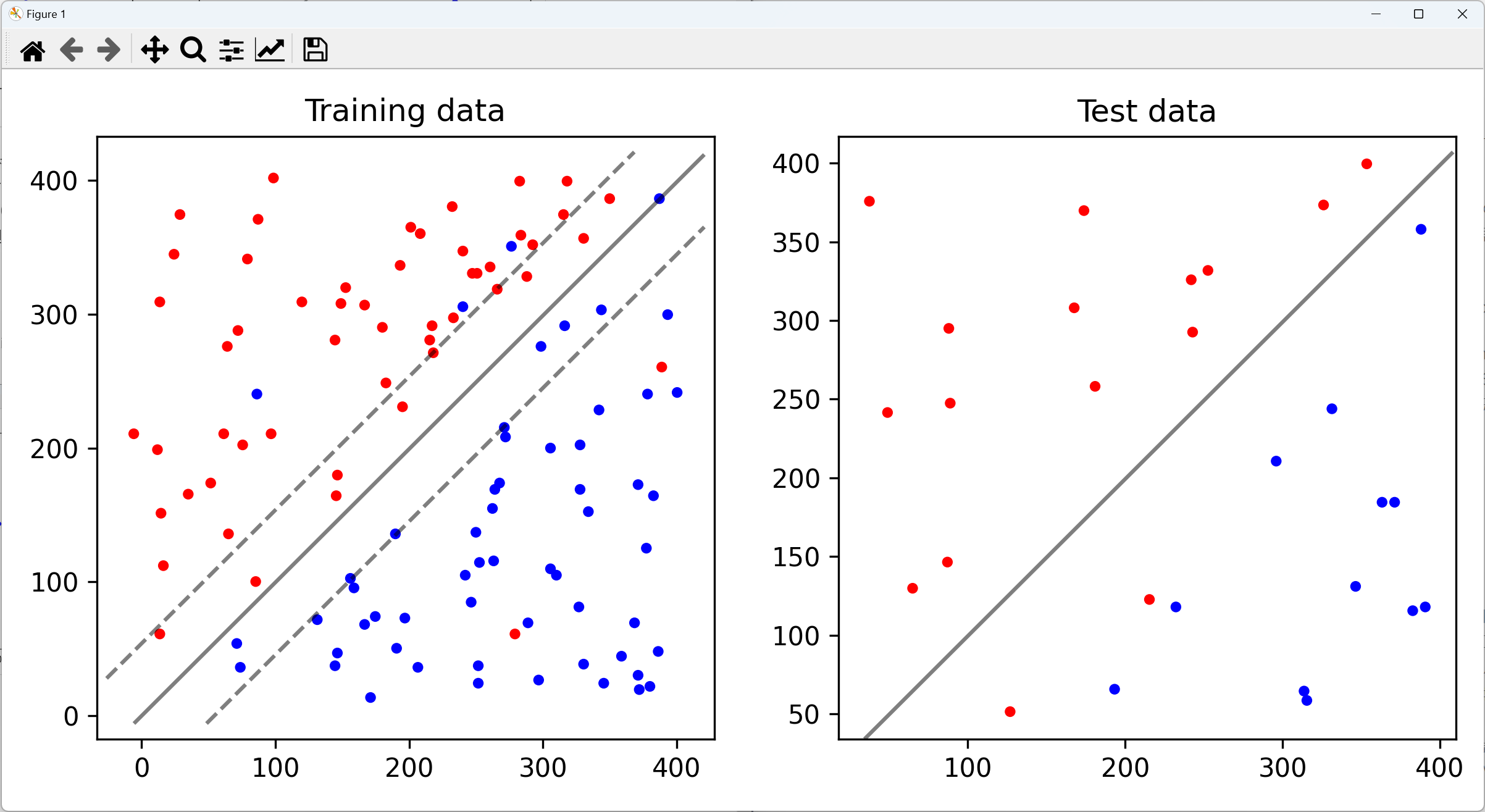
위 사진을 통해 좀 더 쉽게 이해할 수 있다. 이 사진은 위의 코드에서 구현한 두번째 예시이다. margin을 최소화해서 데이터를 분리하면 위의 사진과 같이 Decision Boundary는 non-linear하게 되어지고, 이는 복잡한 비선형 구조가 된다. 이것을 Overfitting, 과적합하다고 표현한다. 훈련 데이터를 과도하게 하면 안된다는 것이다. SVM의 성능을 높이기 위해서는 마진을 잘 두어야한다는 것이다. 그래서 노이즈가 많은 경우 SVM의 파라미터인 C를 높게 주어 마진을 작게 주는 것이 좋다.
error : cv2.error: opencv(4.5.3) ~: error: (-2:unspecified error) the function is not implemented. rebuild the library with windows, gtk+ 2.x or cocoa support.